In today’s hectic IT environments, rapidly getting to the root cause of a service issue and then resolving it is critical. Whether fairly or unfairly, for many IT problems the initial “prime suspect” (or source of the problem) is the network. In addition, the network serves as the foundation on which every IT service is delivered, so ensuring it is always in peak condition is paramount. Finally, chronic shortages and overworked staffing challenges increases the pressure. Because of these observations, it’s important that network and IT teams develop standard, repeatable methods and streamlined processes for all aspects of network management and troubleshooting which is a first step toward full automation initiatives. This blog will provide a topic overview and then dive into specifics ways to achieve operational efficiencies from a troubleshooting perspective via repeatable, consistent techniques.
Why are Standard Network Troubleshooting Processes Important?
There are many reasons why implementing standard troubleshooting procedures are vital to the IT group and the larger organization. Let’s begin first by considering the many benefits for those responsible for maintaining the network infrastructure.
- Operationally, applying standard workflows and polices will result in a consistent, repeatable step-by-step process that can be rolled out enterprise wide. This makes resolution time more predictable, especially crucial because most teams have staff with a range of skills and expertise. For more junior staff, the process will reduce the probability of errors and omissions that might slow resolution time while shortening training times to becoming troubleshooting proficient. In contrast, for senior staff standard procedures enables them to impart their expertise broadly across the team without being called in for every single incident—knowledge transfer offers significant upsides for all involved.
- An added benefit here is the material reduction of support ticket escalation from Tier 1 to Tier 2 or 3. Issues expeditiously resolved sooner rather than later results in reduced staffing headaches, increased efficiencies, and improved IT customer satisfaction leaving more time for proactive network management and resources allocated to improving overall network performance.
- Collaboration and improved cross-team communication are natural, positive by-products as well. Making the sharing of information a core tenet also means coordination across large or geographical disbursed entities are much easier, increasing scalability and improving quality of services delivered. As mentioned above, most network teams are running very lean so getting more done without additional headcount is always a great thing.
- Other often overlooked value includes reporting and documentation. Predefined processes make these activities much easier to maintain, aiding efforts on potential regulatory compliance requirements and subsequent audits. Meanwhile, analysis of past problems can facilitate proactive actions that can minimize future occurrences while also enabling benchmarking and the measuring of team performance.
Everything described so far has tremendous benefits for the larger organization as well. Whether improved customer satisfaction, reduced downtime, or enhanced user experience of stakeholder facing services. It also facilitates the megatrend of process automation, which can further improve network team performance. All of these have top and bottom-line positive implications for business success and growth objectives.
What are the Obstacles to Implementing Workflow Improvements?
Depending on the organization, there may be sufficient urgency that there are few challenges to process improvement initiatives since many larger entities have regulatory or compliance mandates that drive procedural rollouts. In these cases, the obstacles could be more related to ensuring staff follow defined procedures.

In contrast, many small-to-medium entities may not (think they) have resources or expertise to effectively develop standardized techniques. For this situation, it is often best to start small with simpler, “low hanging fruit” actions, then add as required or time permits.
Of course, for businesses of all sizes there is also just simple inertia—”we’ve always done it this (informal) un-documented way and so far, we’ve gotten by” or “we’re too busy putting out fires to expend effort on this”. Both cases are understandable from a human nature perspective, but frequently ignore the significant “hidden costs” of doing nothing. There is also the possible overwhelmingness of where to begin. The next section will offer different suggestions—wherever you are on the “process rollout spectrum”—on how you can enhance what you have done to date, or if only beginning how to start small and build.
Are there Recognized Methods to Rollout Standardized Troubleshooting Procedures?
There are multiple different potential aspects to implementing repeatable, standardized troubleshooting processes. Depending on your organization’s structure, resources, and objectives some or all of these may be valuable. Assuming you are beginning the journey, start with the basics and build from there.

- One straightforward first step would be to create flowcharts or checklists to follow when performing troubleshooting. This does not have to be complicated; it could simply be a document with recommended steps to final problem resolution. Required tools needed at each step should be included. Building on this initiative, Standard Operating Procedures (SOPs) can also be created for more substantial organizations with larger teams.
- Regardless of staff size, periodic training which includes reviewing steps for the most disruptive issues can be helpful when the pressure is on. Again, as above this does not need to be overly sophisticated. It could simply be monthly or quarterly informal meetings where senior staff or the manager review processes, potential tool training, and discusses things learned from past incidents with employees. This last point can be very valuable. There is nothing like the “school of hard knocks”, the reviewing of past problems to educate team members on how best to proceed should they arise again.
- Another relatively easy action that can aid in troubleshooting processes is a dedicated location where everything related to resolving issues is located—a knowledge base where all can contribute their past experiences and expertise. When the pressure is on, having everything in one place for more junior staff is very helpful.
- Implementation of configuration and device management is also an important aspect of troubleshooting processes. Solving problems is best accomplished by having an up-to-date inventory of network endpoints, infrastructure, and configurations which will likely speed time-to-resolution. Change management processes is also a critical aspect as well. Unauthorized or undocumented network updates can be either a source of problems or can slow resolution. In a perfect world with sufficient budget, these activities can be done via automated tools. However, even without this manual, documented processes that are clearly communicated and followed by all stakeholders can be a great first step.
There are also more advanced steps that can aid troubleshooting processes with sufficient resources available. Centralized network monitoring and other automated tools such as ticketing systems. The former will ensure more proactive capabilities are in place speeding mean-time-to-resolution while the latter will offer a formal framework in which the step-by-step actions are performed in the troubleshooting process.
In Summary
Standardized network team troubleshooting processes are an excellent way to improve IT team operational efficiencies and begin automation efforts. Creating streamlined procedures for everyone to follow when network problems arise will speed resolution time, extend staff expertise across the team, improve knowledge transfer to more junior staff, and ultimately make everyone’s day-to-day work experience better. This will also manifest itself across the entire organization resulting in improved service delivery and enhanced customer satisfaction among other things. This blog provides multiple techniques to begin rolling out troubleshooting processes or enhancing current ongoing efforts.
How Link-Live can Help
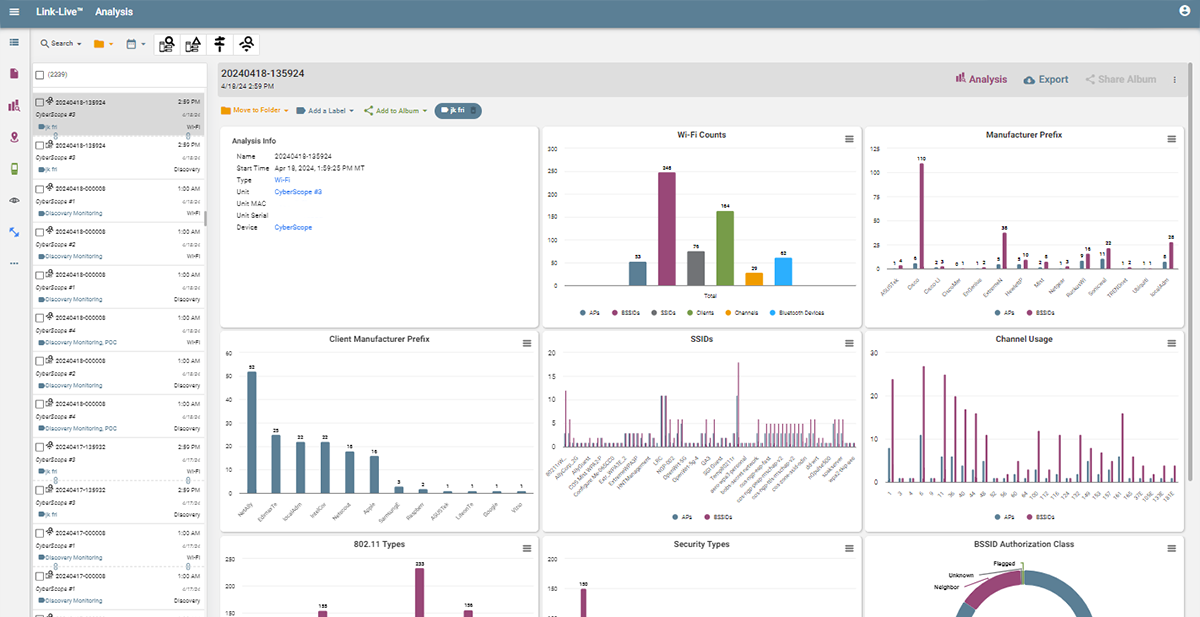
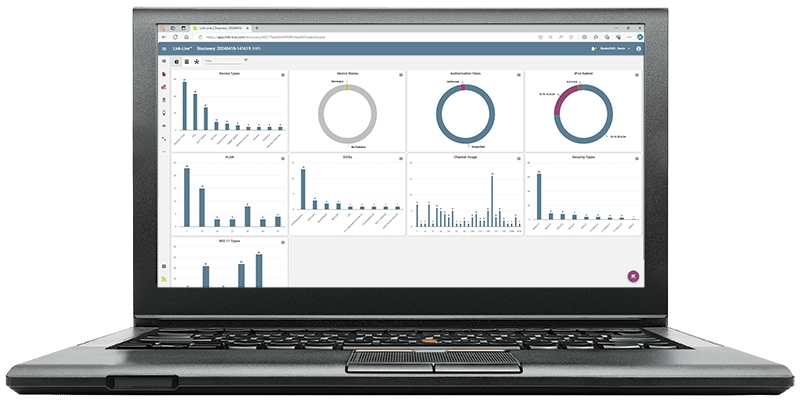
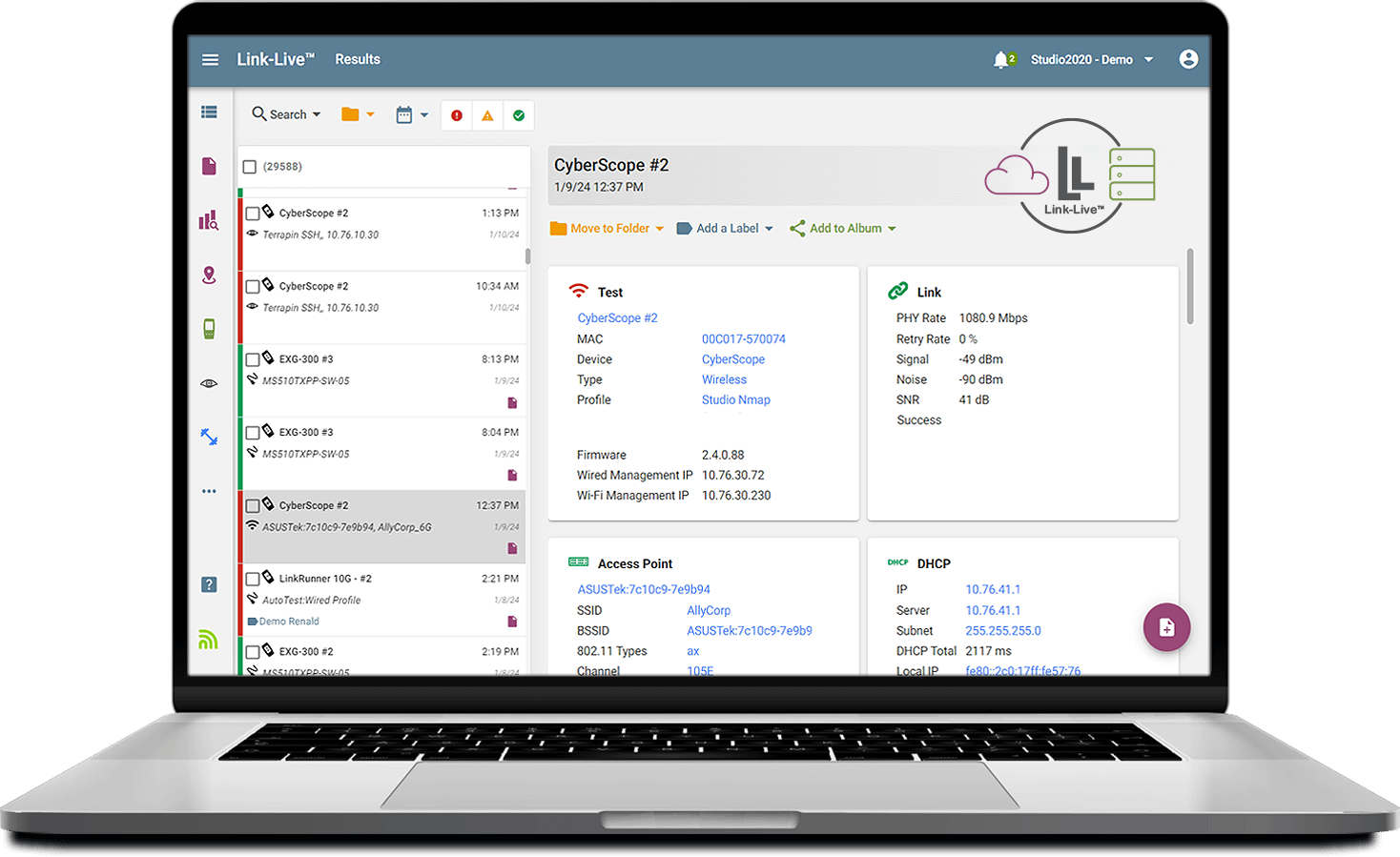
Link-Live is free platform for team collaboration, reporting and analytics. It’s available in conjunction with the entire suite of NetAlly wired, wireless, and security tools is ideal for implementing standard troubleshooting processes and workflows. Link-Live is available as a free cloud service or Link-Live Private edition for licensed private cloud/on-premises deployment.
With unified reporting, advanced topology mapping, analysis, and data management Link-Live ensures teams can efficiently collaborate and share edge network status with all key stakeholders. Its easy-to-use design offers a structured environment, where repeatable step-by-step workflows are simple and on which IT teams processes successfully deployed. Link-Live is the perfect tool to extend your troubleshooting process initiatives to the edge network.